
Distributed processes fall into two categories: open and closed. Open processes are started in one service and will finish in another after passing through any number of services in between. Closed processes are driven by one particular service from start to finish, and while other services may be involved, the originating service is in overall control of the process. Every distributed system will have examples of each, and you’ll often see processes that the business considers highly critical implemented in either way.
Sending data to a BI system is an example of an open process. Any service raising events or saving data does not care about how successfully that data gets into management reports. In the distributed world of micro-architectures, especially with the broad adoption of serverless functions, it’s common to see distributed processes hop linearly from one service to the next, until some desired final state is reached.
Conversely, a service can also be aware that a given process requires several steps to complete and can manage the progression through these steps. Other services may be involved, but the originating service cares about the successful completion of each external task; the process is closed. An example of such a scenario could be a Sales service which is aware of a customer’s activities from the point of first placing something in a cart, to checking out and paying. It might be that the service is able to detect when a cart is left open and send a reminder to the customer, acting in an ‘outbound sales’ capacity.
Although it’s inevitable for both styles of processes to exist, I think some care has to be taken when the business starts to depend heavily on one or more open processes.
Why close the loop?

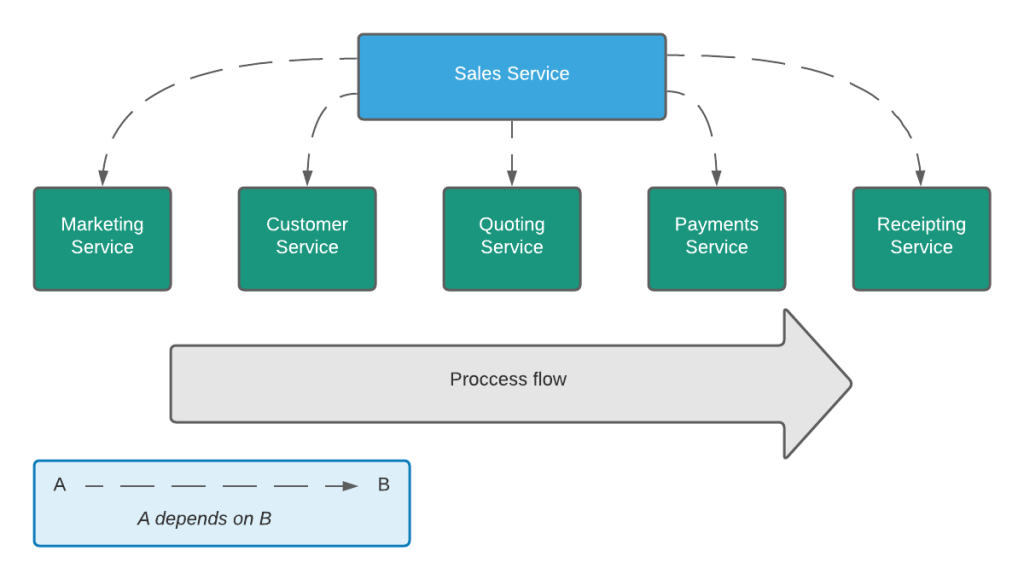
This diagram of an open process shows a very common flow which has been implemented countless times by e-commerce sites. Problems start to occur when the business begins to do more than just sell on the happy path. To know that a quote hasn’t been converted, the Payments Service would need to know that the quote exists, or the Quoting Service would have to be sat waiting for an update from the Payments Service. Having these services know so much about how they interact with each other introduces a form of direct coupling which is a problem.
This might not sound like such a big deal, but as is so often the case with software engineering, the biggest problems are bought about gradually. This type of coupling is a death of a thousand cuts; over time the scope of each service becomes muddied so it gets difficult to tell where new logic belongs. Changes in one service can also have unexpected consequences in another service.
“Aha!” I hear you cry: “But isn’t this what testing is for?”
And you’re right, of course – these scenarios can be tested at an integration level. It shouldn’t be too difficult for QA engineers to add such scenarios to an automation suite, which will get run regularly. The business will then begin to trust these tests and rely on them increasingly, placing significant focus on trying to prevent bugs being released to production.
But let’s think back to our first ever lesson in software testing, to the testing pyramid. I put together a testing pyramid of my own not so long ago here, which looked like this:
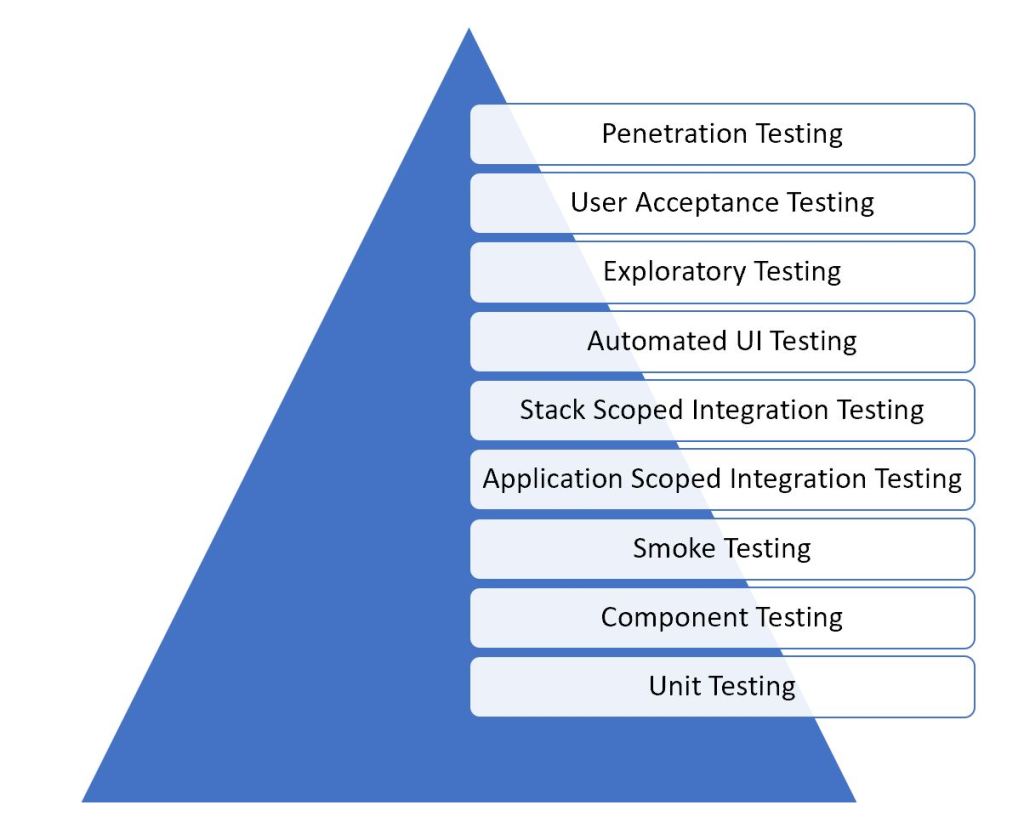
The kind of testing needed in this highly trusted automation suite is Stack Scoped Integration Testing, which is about half way up on my pyramid. That means that there are significantly less costly stages at which to find these bugs. The problem that this system is descending into is often called a Distributed Monolith – where we have all of the downsides of distributed architecture but without any of the clean decoupling. Verifying this open process is not something that can be done at the level of a unit test.
The closed version
The need for a large automation suite covering any given stack of services suggests there’s more going on than there are services to handle. If something is important enough to warrant extensive testing, it’s probably important enough to warrant its own service to encapsulate what is being tested.
This is ‘closed’ because the distributed part of this process begins and ends in the Sales Service. The Sales Service knows what’s going on at the next level of abstraction above the more focused ‘worker’ services. Allowing them to simply get on with what they do best, without being exposed to external concepts.
In this model, testing can begin at the unit level. There can be developer written integration tests scoped on just the Sales Service. This is FAR better for ensuring quality than the automation suite alone; test what’s being written in preference to testing what’s about to be released.
There will be some who read this and think to themselves: “Ah, it’s an Enterprise Service Bus!” – they’re wrong. On one level, this does what an ESB generally promises to do but fails to deliver on because of one important difference – none of the worker services are aware of the Sales Service. The Sales Service can listen for events from the worker services and it can send commands to the worker services (even via HTTP), but the Sales Service will never raise an event that a worker service is interested in, and none of the workers would ever talk directly to the Sales Service. The Sales Service depends on the worker services, but the worker services depend on neither the Sales Service nor each other.
Each worker service owns the contract for every way which it communicates, whether for the commands it receives, the events it raises, or HTTP endpoints it exposes. So each worker service should also have consumer contract tests (consumer contract tests are discussed here) for all consumers proving a developer hasn’t broken anything. Any changes to the Sales Service can’t possibly break the other services as they don’t depend on the Sales Service in any way.
Is dependency inversion really so important?
Short answer: “Yes”.
But for a quick thought experiment, imagine these five worker services raise five events each, can each respond to five different commands, and have five different HTTP endpoints exposed. For each worker service, that’s 15 contracts. Services interacting with a worker service are attempting to carry out something which is limited in scope to what that specific worker service does. The number consumer contract tests required to be running in the dev pipeline for each service is not huge. What’s more, the tests are all focused on triggering business logic which a developer working on a service would be familiar with.
Now let’s reverse the situation and have everything depending on the Sales Service. The Sales Service now owns contracts which the worker services consume; possibly 15 per service. That means possibly 75 contracts (for just 5 services)! It’s also five times the number of consumer contracts. Preventing defects is significantly more complicated when we introduce one big universal dependency. As this system of services grows we are inevitably going to find increased numbers of bugs getting into production, significantly higher development costs, and unbelievably slow delivery.
The pattern
To sum things up, I guess this is touching on the universal pattern for quality: if something is important move the quality gates to ‘the left’. In software delivery, ‘the left’ indicates earlier stages of the software development life cycle. If you have a growing automation suite, you might have an excellent QA team, but you might also have a few missing services.




Leave a comment