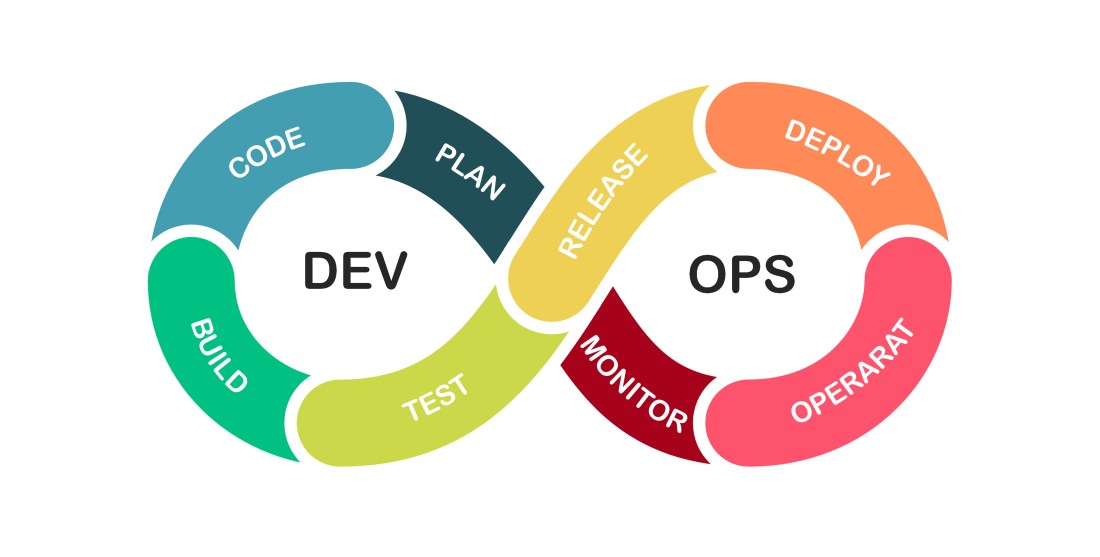
Software quality thrives not on excelling in one area but on maintaining competence across multiple layers of delivery. Each layer acts as a filter, removing around two thirds of defects. Focusing solely on one element, like exhaustive testing, leads to diminishing returns. Collaborative approaches across testing, CI/CD, and requirements prevent issues effectively.
Achieving Software Quality Through Layered Practices