
A simple but flexible package to turn your commandline project into either a Windows Service or a Linux systemd service.
Helpful.Hosting.WorkerService.Windows/Systemd

A simple but flexible package to turn your commandline project into either a Windows Service or a Linux systemd service.

Decoupled architecture is one of the biggest enablers of agility, speedy delivery, and high quality; yet many software designers have limited experience of what decoupled looks like. I hear people talk about different amounts of indirection and API layers, without understanding that these don't inherently decouple. I've been confronted with the insistence that because there's … Continue reading How to Design Decoupled Systems
This is a very simple DotNet Standard 2.0 package for receiving messages from AWS SQS in as simple a manner as I think is possible. Source code is on github https://github.com/RokitSalad/Helpful.Aws.Sqs.Receiver The package is available on nuget.org: https://www.nuget.org/packages/Helpful.Aws.Sqs.Receiver The package provides a few useful features which you don't get by default when using the AWS … Continue reading Helpful.Aws.Sqs.Receiver
"Don't overengineer this. We need to move as fast as we can."Too many business representatives The Agile Manifesto is built on 12 pillars, the 9th of which (at the time of writing) is: Continuous attention to technical excellence and good design enhances agility. I regard the Agile Manifesto as a thing of truth. It has … Continue reading Technical Excellence
Distributed processes fall into two categories: open and closed. Open processes are started in one service and will finish in another after passing through any number of services in between. Closed processes are driven by one particular service from start to finish, and while other services may be involved, the originating service is in overall … Continue reading Open vs Closed Distributed Processes
I've been building microservices for several years. I've mostly used DotNet, DotNet Core, and Ruby on Rails to build them, and I've generally deployed them either into AWS EC2, or Azure Service Fabric. I've found most enterprises aren't ready for managing microservices in containers, either in the cloud or their own data centres. Keeping things … Continue reading Microservices with AWS Lambda
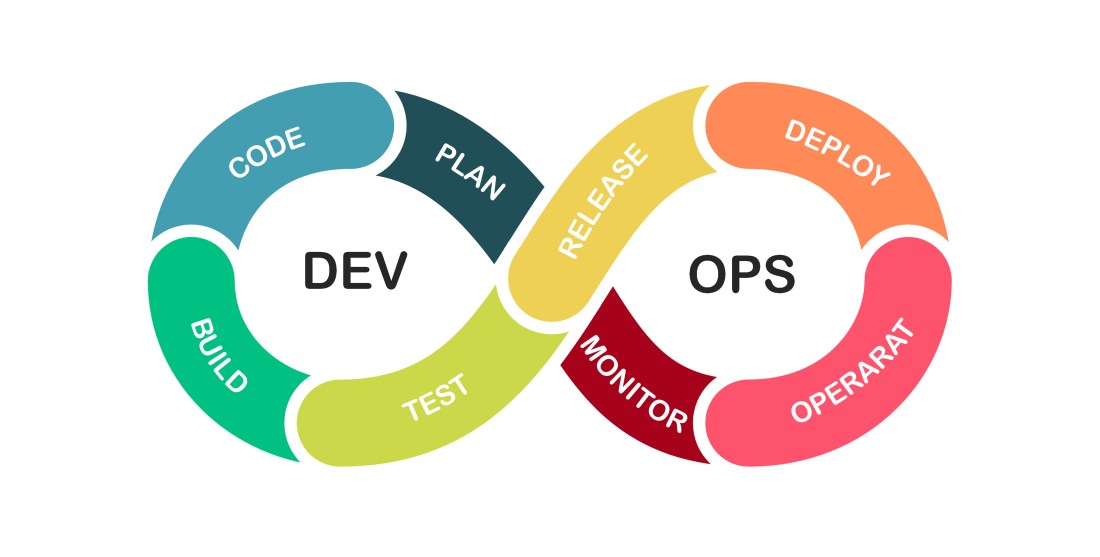
When implemented correctly, DevOps reaches beyond the Development teams and becomes a unifying strategy for the entire enterprise.
Does Conway's Law have a dark side?
Quickly configure Azure DevOps to deploy your new application into AWS.

Let Coding Daddy answer your remote team management woes...
